c++FFMPEG音视频开发的坑与细节
音视频文件解码流程
打开文件获取文件上下文
首要任务就是获取文件上下文,查找流信息
extern "C" {
#include <libavformat/avformat.h>
}
int main() {
AVFormatContext *pAvFormatCtx;
//获取文件上下文
int res = avformat_open_input(&pAvFormatCtx,"./test.mp4",nullptr,nullptr)
if (!res) {
//打开失败
return -1;
}
//获取文件流信息
//此函数会自动从文件头部或从少量的帧中分析补全pAvFormatCtx上下文中的媒体流信息
//例如:
//流的类型(视频、音频、字幕等)。
//编解码器信息(codec ID、参数等)。
//分辨率(对于视频流)。
//采样率、声道数(对于音频流)。
//帧率、时长、比特率等元数据。
res = avformat_find_stream_info(pAvFormatCtx,nulltpr);
if (res == AVERROR_EOF) {
//获取失败
return -1;
}
}注意这里avformat_open_input中pAvFormatCtx传递的是指针的指针,这样就能在函数内部自动为pAvFormatCtx声明内存
遍历媒体流获取想要的视频和音频流的解码器上下文
extern "C" {
#include <libavcodec/avcodec.h>
}
AVStream *pAvStream;
AVCodecContext *pVidCodecCtx;
int VidStreamIndex = -1;
AVCodecContext *pAudCodecCtx;
int AudStreamIndex = -1;
for (int i = 0;i < pAvFormatCtx->nb_streams;i++) {
pAvStream = pAvFormatCtx->streams[i];
if (pAvStream->codecpar->codec_type == AVMEDIA_TYPE_VIDEO) { //判断类型为视频
//找到只用于此流的解码器
const AVCodec *pVidCodec = avcodec_find_decoder(pAvStream->codecpar->codec_id);
if (pVidCodec == nullptr) {
//找不到适用于pAvStream->codecpar->codec_id的视频解码器
return -1;
}
//分配解码器上下文
pVidCodecCtx = avcodec_alloc_context3(pVidCodec);
// 设置视频解码器上下文参数
int res = avcodec_parameters_to_context(pVidCodecCtx, pAvStream->codecpar);
if (res < 0)
{
//设置视频解码器上下文参数失败
avcodec_free_context(&pVidCodecCtx);
return -1;
}
// 打开视频解码器
res = avcodec_open2(pVidCodecCtx, pVidCodec, nullptr);
if (res < 0)
{
//打开视频解码器失败
avcodec_free_context(&pVidCodecCtx);
return -1;
}
VidStreamIndex = i;
} else if(pAvStream->codecpar->codec_type == AVMEDIA_TYPE_AUDIO) { //类型为音频
//找到只用于此流的解码器
const AVCodec *pAudCodec = avcodec_find_decoder(pAvStream->codecpar->codec_id);
if (pAudCodec == nullptr) {
//找不到适用于pAvStream->codecpar->codec_id的音频解码器
return -1;
}
//分配解码器上下文
pAudCodecCtx = avcodec_alloc_context3(pAudCodec);
// 设置视频解码器上下文参数
int res = avcodec_parameters_to_context(pAudCodecCtx, pAvStream->codecpar);
if (res < 0)
{
//设置视频解码器上下文参数失败
avcodec_free_context(&pAudCodecCtx);
return -1;
}
// 打开视频解码器
res = avcodec_open2(pAudCodecCtx, pAudCodec, nullptr);
if (res < 0)
{
//打开视频解码器失败
avcodec_free_context(&pAudCodecCtx);
return -1;
}
AudStreamIndex = i;
}
}这里需要记录VidStreamIndex和AudStreamIndex方便后续调用
读取数据包
媒体文件储存时是将各个流拆成若干数据包,再将数据包一个接一个的存储进文件的
所以要先读取数据包在更具数据包的媒体流的序号添加经一个列队,还原出我们要的媒体流
std::queue<AVPacket *> m_vidPacketQueue;
std::queue<AVPacket *> m_audPacketQueue;
int res = 0;
AVPacket *pPacket = av_packet_alloc();
if (!m_pAvFormatCtx)
{
return -1;
}
// 读取数据包
res = av_read_frame(m_pAvFormatCtx, pPacket);
if (res == AVERROR_EOF)
{
//读取到文件结尾
return res;
} else if (res < 0)
{
//读取数据包失败
return res;
}
if (pPacket->stream_index == VidStreamIndex)
{
m_vidPacketQueue.push(pPacket);
}
else if (pPacket->stream_index == AudStreamIndex)
{
m_audPacketQueue.push(pPacket);
}从数据包解码出帧数据
AVPacket *pPacket = packetQueue.front();
AVFrame* pOutFrame = av_frame_alloc();
int res = 0;
//将包送入解码器上下文
res = avcodec_send_packet(pCodecCtx, pPacket);
if (res == AVERROR(EAGAIN))
{
//缓冲区已满
}
else if (res == AVERROR_EOF) // 数据包送入结束不再送入,但是可以继续可以从内部缓冲区读取解码后的音视频帧
{
//数据包送入结束不再送入,但是可以继续可以从内部缓冲区读取解码后的音视频帧
}
else if (res < 0) // 送入输入数据包失败
{
//送入数据包失败
return res;
}
//从解码器上下文那出处理好的帧
res = avcodec_receive_frame(pCodecCtx,pOutFrame);
if (res == AVERROR(EAGAIN))
{
//应为packet没有完整的帧或非关键帧需要后续的帧来推理
//需要更多数据包
av_frame_free(&pOutFrame);
return res;
} else if (res == AVERROR_EOF)
{
//解包完毕后续不会再有包了
av_frame_free(&pOutFrame);
return res;
} else if (res < 0)
{
//解包失败
av_frame_free(&pOutFrame);
}对应视频帧进行转换
当视频帧格式目标系统无法播放时,就需要对视频视频帧进行转换
视频帧转化函数
struct OutVideoFrameSetting
{
int32_t width = 0;
int32_t height = 0;
AVPixelFormat pixelFormat = AV_PIX_FMT_RGB32;
};
int32_t Codec::videoFrameConvert(const AVFrame *pInFrame, OutVideoFrameSetting &settings , uint8_t* data[1],int linesize[1])
{
// 计算缩放比例(等比例缩放,使得图像能完整显示在目标画布内)
int width = settings.width;
int height = settings.height;
if (settings.width <= 0 ||settings.height <= 0){
width = pInFrame->width;
height = pInFrame->height;
}
double ratioWidth = (double)width / pInFrame->width;
double ratioHeight = (double)height / pInFrame->height;
double ratio = std::min(ratioWidth, ratioHeight);
int newWidth = static_cast<int>(pInFrame->width * ratio);
int newHeight = static_cast<int>(pInFrame->height * ratio);
int xOffset = (width - newWidth) / 2;
int yOffset = (height - newHeight) / 2;
// 确保输出缓冲区已分配并足够大,这里采用 RGB32,每个像素4字节
// 如果输出内存未分配,则需先分配内存
// 示例:假如你未在调用前准备内存,则可在此分配临时内存
const AVPixFmtDescriptor* desc = av_pix_fmt_desc_get(settings.pixelFormat);
if (!desc) {
qWarning() << "无法获取像素格式描述";
return -1;
}
int bytesPerPixel = av_get_bits_per_pixel(desc) / 8;
// 填充目标画布为黑色背景
for (int y = 0; y < height; y++) {
memset(data[0] + y * linesize[0], 0, width * bytesPerPixel);
}
// 为缩放后的图像分配临时缓冲区
uint8_t *tempData[4] = { nullptr };
int tempLinesize[4] = { 0 };
int ret = av_image_alloc(tempData, tempLinesize, newWidth, newHeight, settings.pixelFormat, 1);
if (ret < 0) {
return ret;
}
// 创建缩放上下文
SwsContext *swsCtx = sws_getContext(
pInFrame->width, pInFrame->height, (AVPixelFormat)pInFrame->format,
newWidth, newHeight, settings.pixelFormat,
SWS_BILINEAR, nullptr, nullptr, nullptr);
if (!swsCtx) {
av_freep(&tempData[0]);
return -1;
}
// 执行缩放转换
int scaledH = sws_scale(
swsCtx,
pInFrame->data, pInFrame->linesize,
0, pInFrame->height,
tempData, tempLinesize);
sws_freeContext(swsCtx);
if (scaledH != newHeight) {
av_freep(&tempData[0]);
return -1;
}
// 将缩放后的图像拷贝到目标画布居中位置
for (int y = 0; y < newHeight; y++) {
memcpy(
data[0] + ((y + yOffset) * linesize[0] + xOffset * bytesPerPixel),
tempData[0] + y * tempLinesize[0],
newWidth * bytesPerPixel);
}
av_freep(&tempData[0]);
return 0;
}音频帧格式转码
//初始化重采样上下文
int32_t Codec::initAudioContext()
{
// 分配 SwrContext
pSwrCtx = swr_alloc();
if (!pSwrCtx) {
qWarning() << "分配重采样上下文失败";
return -1;
}
// 配置输出声道布局
AVChannelLayout out_ch_layout;
av_channel_layout_default(&out_ch_layout, m_outAudSetting.channel_count);
// 根据采样位深选择输出采样格式
AVSampleFormat out_format = AV_SAMPLE_FMT_NONE;
switch (m_outAudSetting.sample_fmt) {
case 8:
out_format = AV_SAMPLE_FMT_U8;
break;
case 16:
out_format = AV_SAMPLE_FMT_S16;
break;
case 24:
out_format = AV_SAMPLE_FMT_S32;
break;
case 32:
out_format = AV_SAMPLE_FMT_FLT;
break;
case 63:
out_format = AV_SAMPLE_FMT_DBL;
break;
default:
qWarning() << "不支持的采样位深:" << m_outAudSetting.sample_fmt;
swr_free(&pSwrCtx);
return -1;
}
// 配置重采样参数
int res = swr_alloc_set_opts2(&pSwrCtx,
&out_ch_layout,
out_format,
m_outAudSetting.sample_rate,
&(m_pAvFormatCtx->streams[m_audStreamIndex]->codecpar->ch_layout),
static_cast<AVSampleFormat>(m_pAvFormatCtx->streams[m_audStreamIndex]->codecpar->format),
m_pAvFormatCtx->streams[m_audStreamIndex]->codecpar->sample_rate,
0,
nullptr);
qDebug() << "audio sample_rate: " << m_pAvFormatCtx->streams[m_audStreamIndex]->codecpar->sample_rate;
if (res < 0) {
qWarning() << "配置重采样上下文失败:" << res;
swr_free(&pSwrCtx);
return res;
}
// 提高重采样质量
//swr_set_quality(pSwrCtx, 10); // 设置最高质量
// 初始化 SwrContext
res = swr_init(pSwrCtx);
if (res < 0) {
qWarning() << "初始化重采样上下文失败:" << res;
swr_free(&pSwrCtx);
return res;
}
return 0;
}
int32_t Codec::audioFrameConvert(const AVFrame *pInFrame, OutAudioFrameSetting &settings, uint8_t *data[1], int linesize[1])
{
if (!pInFrame) {
qWarning() << "pInFrame is null";
return -1;
}
int in_samples = pInFrame->nb_samples;
// 计算重采样延时并根据采样率比例重算输出采样点数
if (!pSwrCtx) return -1;
int64_t delay = swr_get_delay(pSwrCtx, m_pAvFormatCtx->streams[m_audStreamIndex]->codecpar->sample_rate);
int out_samples = av_rescale_rnd(delay + in_samples,
settings.sample_rate,
m_pAvFormatCtx->streams[m_audStreamIndex]->codecpar->sample_rate,
AV_ROUND_UP);
AVChannelLayout out_ch_layout;
av_channel_layout_default(&out_ch_layout, m_outAudSetting.channel_count);
// 根据采样位深选择输出采样格式
AVSampleFormat out_format = AV_SAMPLE_FMT_NONE;
switch (m_outAudSetting.sample_fmt) {
case 8:
out_format = AV_SAMPLE_FMT_U8;
break;
case 16:
out_format = AV_SAMPLE_FMT_S16;
break;
case 24:
out_format = AV_SAMPLE_FMT_S32;
break;
case 32:
out_format = AV_SAMPLE_FMT_FLT;
break;
case 63:
out_format = AV_SAMPLE_FMT_DBL;
break;
default:
qWarning() << "不支持的采样位深:" << m_outAudSetting.sample_fmt;
return -1;
}
// 分配输出缓冲区
int res = av_samples_alloc(data, linesize,
out_ch_layout.nb_channels,
out_samples,
out_format,
0);
if (res < 0) {
qWarning() << "分配缓冲区失败";
return -1;
}
// 执行重采样转换
int converted_samples = swr_convert(pSwrCtx,
data,
out_samples,
pInFrame->data,
in_samples);
m_outAudSetting.sample = m_outAudSetting.sample<converted_samples ? converted_samples : m_outAudSetting.sample;
if (converted_samples < 0) {
qWarning() << "重采样转换失败:" << converted_samples;
av_freep(&data[0]);
return -1;
}
//m_outAudSetting.sample = converted_samples;
// 可选:重新计算输出数据大小
linesize[0] = av_samples_get_buffer_size(nullptr,
out_ch_layout.nb_channels,
converted_samples,
out_format,
0);
if (linesize[0] < 0) {
qWarning() << "计算输出缓冲区大小失败";
av_freep(&data[0]);
return -1;
}
return converted_samples;
}坑点1:重采样器上下文不可以反复创建
冲裁样器上下文一定要提前创建好避免反复创建,应为在对音频重采样时数据长度会发生改变,所以重采样器上下文中有缓冲区
重复创建,缓冲区就会被重置导致音频被数据被截断,最后导致音频播放时出现卡顿、杂音、速度声调不正确等问题;
坑点2:使用SDL回调模式播放时卡顿的问题
SDL_OpenAudioDevice中audio_spec.samples参数要设置为swr_convert转换后返回的最大一次的大小,还要确保是2的幂
如果不是就-1
或者 当没填满audio_spec.samples时先将结果缓存处理到大小等于audio_spec.samples时再返回
播放数据
此时就可以将处理好的数据通过QT或SDL等框架播放出去了
音视频同步
什么是PTS
在音视频处理中,PTS(Presentation Time Stamp,呈现时间戳)是用于表示媒体帧(视频帧或音频帧)应该被呈现(播放)的时间的元数据。它是音视频同步和播放顺序控制的核心。
在FFMPEG中PTS 通常以流的时基(time_base)为单位,在 FFmpeg 中需要通过 av_q2d(stream->time_base) 将时基转换为秒。
例如,视频流的时基可能是 1/25表示一帧持续0.04秒,每秒也就是25帧
当PTS为500时就表示这是第500帧,也就是就是第 500*0.05=25秒。
将PTS从以流的时基(time_base)为单位转换为秒为单位代码:
double audioPts = frame->pts * av_q2d(m_pAvFormatCtx->streams[m_audStreamIndex]->time_base);同步方式
一般有三种同步方式
音频更新时钟视频向音频同步这种方法最为常见
视频更新时钟音频向音频同步这种方法特点就是在性能不足时画面保持流畅但是音频卡顿
时钟单独维护,音频和视频都各自向时钟同步这种方法适用于需要精细控制事件轴的场景,比如剪辑软件
这里我才用第一种音频更新时钟视频向音频同步的方法
应为人体对听觉的敏感度比视觉大,所以优先保持听觉感受时重要的。
同步时钟的设计
class AVSync
{
public:
AVSync(){
start_ = std::chrono::steady_clock::now();
};
void InitClock(){
setClock(NAN);
}
void setClockAt(double pts, double time){
pts_ = pts;
pts_drift_ = pts_ - time;
}
double getClock(){
double time = GetSeconds();
return pts_drift_ + time;
}
void setClock(double pts){
double time = GetSeconds();
setClockAt(pts,time);
}
double GetSeconds(){
auto now = std::chrono::steady_clock::now();
std::chrono::duration<double> diff = now - start_;
return diff.count();
}
// ...existing code...
double pts_ = 0;
double pts_drift_ = 0;
private:
std::chrono::steady_clock::time_point start_;
};GetSeconds()用来获取当前运行过的事件
pts_为音频播放到的时间
pts_drift_为相运行时间的偏移量
同步机制
- 假设视频帧的 PTS 为 5.0 秒,系统时间为 10.0 秒,调用
setClockAt(5.0, 10.0):pts_= 5.0。pts_drift_= 5.0 - 10.0 = -5.0。
- 之后,调用
getClock:- 如果过去了2秒,系统要开始解码新的视频帧了,当前系统时间为 12.0 秒,则
getClock返回 -5.0 + 12.0 = 7.0 秒。 - 这表示当前播放进度为 7.0 秒,视频帧的 PTS 应与此值匹配。
- 如果过去了2秒,系统要开始解码新的视频帧了,当前系统时间为 12.0 秒,则
通过不断更新 pts_ 和 pts_drift_,AVSync 可以跟踪媒体播放的进度,并与系统时间保持一致。
同步过程
首先播放音频使用了sdl回调模式这样当播完一段数据后会自动通过回调函数去索取新的数据
这样只需要在回调函数执行返回数据时使用setClock更新时钟就行
视频帧处理
解码后的视频帧的显示会根据当前视频帧PTS和基准时钟(通过getClock获取)来控制显示:
(1)当前视频帧的PTS >= 基准时钟: (视频帧解码处理很快,这种情况极少)
直接延长当前视频帧的显示时间即可。
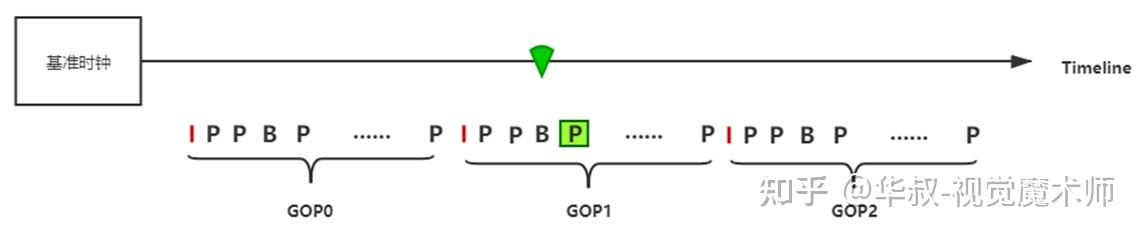
(2)当前视频帧的PTS < 基准时钟 < 下一GOP开始时间点:
当前视频帧解码后直接丢弃,开始解码后续帧,一直解码到与全局时钟平齐的视频帧 。如果GOP中帧数比较大,当前PTS与全局时钟差距也比较大,这里的连续解码也会消耗过多的时间。这种情况下性能优先(质量可降低)时,可以快速跳转到平齐的P或B帧解码,但是这种情况下大概率会出现马赛克,直到下一个GOP才可以规避马赛克。
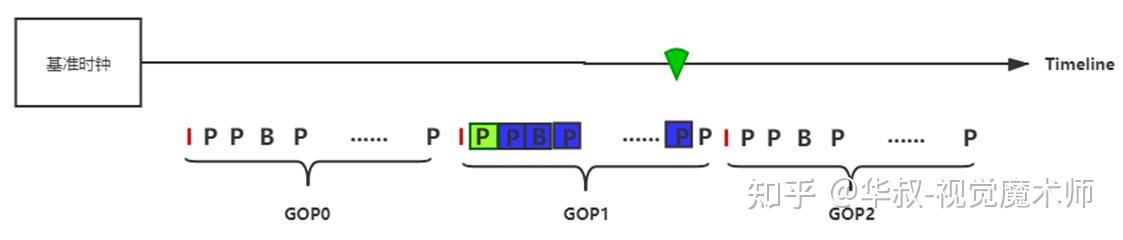
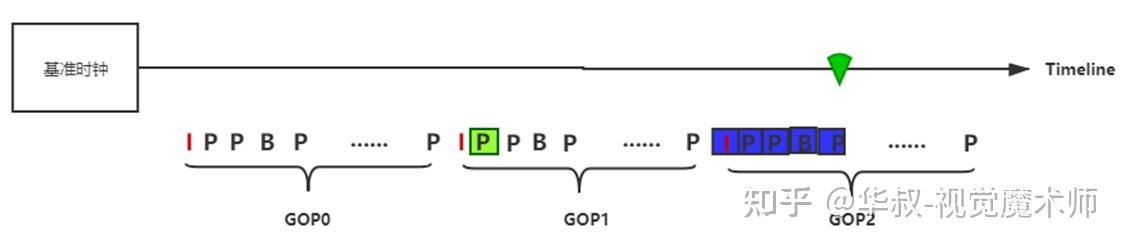
(3)当前视频帧的PTS <下一GOP开始时间点 < 基准时钟 :
找到全局时钟对应的GOP,从I帧开始开始依次解码,一直解码到与全局时钟平齐的视频帧。如果GOP中帧数比较大,当前PTS与全局时钟差距也比较大,这里的连续解码也会消耗过多的时间。这种情况下性能优先(质量可降低)时,可以快速跳转到平齐的P或B帧解码,但是这种情况下大概率会出现马赛克,直到下一个GOP才可以规避马赛克。
变速
变速主要考虑音频,因为视频会随着音频自动同步
如何缩短音频的播放时间
音频的播放时长取决于两个因素:
- 样本数:音频数据包含多少个样本(sample)。
- 采样率:每秒播放多少个样本(单位是 Hz,例如 44100 Hz 表示每秒播放 44100 个样本)。
播放时长可以通过以下公式计算: 例如:
- 有 44100 个样本,采样率为 44100 Hz,播放时长 = 4410044100=1 秒。
- 如果采样率变成 22050 Hz(减半),时长 = 2205044100=2 秒,播放变慢。
- 如果采样率变成 88200 Hz(翻倍),时长 = 8820044100=0.5 秒,播放变快。
核心点:改变采样率会直接影响播放时长,因为它决定了样本被“挤压”或“拉伸”到多长时间内播放。
将视频重采样到采样率22050Hz或88200Hz的内容在44100的设备播放就实现的倍速效果
问题:会导致音调发生改变
应为拉升/压缩了采样率,所以声音就会变调
解决方法:使用滤镜变速
int32_t Codec::initAudioFliter()
{
// 初始化滤镜
filter_graph = avfilter_graph_alloc();
if (!filter_graph) {
//分配滤镜图失败
swr_free(&pSwrCtx);
return -1;
}
// 输入滤镜:abuffer
const AVFilter *abuffer = avfilter_get_by_name("abuffer");
if (!abuffer) {
//找不到 abuffer 滤镜
return -1;
}
AVCodecParameters *par = m_pAvFormatCtx->streams[m_audStreamIndex]->codecpar;
char args[512];
snprintf(args, sizeof(args),
"time_base=%d/%d:sample_rate=%d:sample_fmt=%s:channel_layout=0x%" PRIx64,
m_pAvFormatCtx->streams[m_audStreamIndex]->time_base.num,
m_pAvFormatCtx->streams[m_audStreamIndex]->time_base.den,
par->sample_rate,
av_get_sample_fmt_name((AVSampleFormat)par->format),
par->ch_layout.u.mask);
int res = avfilter_graph_create_filter(&buffersrc_ctx, abuffer, "in", args, nullptr, filter_graph);
if (res < 0) {
//创建 abuffer 滤镜失败
return -1;
}
// 变速滤镜:atempo
const AVFilter *atempo = avfilter_get_by_name("atempo");
if (!atempo) {
//找不到 atempo 滤镜
return -1;
}
snprintf(args, sizeof(args), "tempo=%f", playback_speed);
AVFilterContext *atempo_ctx;
res = avfilter_graph_create_filter(&atempo_ctx, atempo, "atempo", args, nullptr, filter_graph);
if (res < 0) {
//创建 atempo 滤镜失败
return -1;
}
// 输出滤镜:abuffersink
const AVFilter *abuffersink = avfilter_get_by_name("abuffersink");
if (!abuffersink) {
//找不到 abuffersink 滤镜
return -1;
}
res = avfilter_graph_create_filter(&buffersink_ctx, abuffersink, "out", nullptr, nullptr, filter_graph);
if (res < 0) {
//创建 abuffersink 滤镜失败
return -1;
}
// 配置输出格式(与 SwrContext 输入一致)
int out_sample_rates[] = {m_pAvFormatCtx->streams[m_audStreamIndex]->codecpar->sample_rate, -1};
//av_channel_layout_default(&out_ch_layout, m_outAudSetting.channel_count);
//uint64_t out_channel_layouts = m_pAvFormatCtx->streams[m_audStreamIndex]->codecpar->ch_layout.u.mask;
int64_t out_channel_layouts[] = {m_pAvFormatCtx->streams[m_audStreamIndex]->codecpar->ch_layout.u.mask,-1};
int out_formats[] = {m_pAvFormatCtx->streams[m_audStreamIndex]->codecpar->format, -1};
av_opt_set_int_list(buffersink_ctx, "channel_layouts", out_channel_layouts, -1, AV_OPT_SEARCH_CHILDREN);
av_opt_set_int_list(buffersink_ctx, "sample_rates", out_sample_rates, -1, AV_OPT_SEARCH_CHILDREN);
av_opt_set_int_list(buffersink_ctx, "sample_fmts", out_formats, -1, AV_OPT_SEARCH_CHILDREN);
// 链接滤镜
res = avfilter_link(buffersrc_ctx, 0, atempo_ctx, 0);
if (res < 0) {
//链接 abuffer 到 atempo 失败
return -1;
}
res = avfilter_link(atempo_ctx, 0, buffersink_ctx, 0);
if (res < 0) {
//链接 atempo 到 abuffersink 失败
return -1;
}
// 配置滤镜图
res = avfilter_graph_config(filter_graph, nullptr);
if (res < 0) {
//配置滤镜图失败
return -1;
}
return 0;
}
if(m_audBuffer.empty()) return -1;
// 从缓冲区取出一帧
AVFrame *frame = m_audBuffer.front();
m_audBuffer.pop();
double audioPts = frame->pts * av_q2d(m_pAvFormatCtx->streams[m_audStreamIndex]->time_base);
//将音频帧送入滤镜
res = av_buffersrc_add_frame(buffersrc_ctx, frame);
if (res < 0) {
//送入滤镜失败:
av_frame_free(&frame);
filter_graph_mutex.unlock();
return -1;
}
// 从滤镜获取处理后的帧
AVFrame *filt_frame = av_frame_alloc();
res = av_buffersink_get_frame(buffersink_ctx, filt_frame);
if (res < 0) {
//从滤镜获取帧失败
av_frame_free(&filt_frame);
filter_graph_mutex.unlock();
return -1;
}